Versioning / Snapshots
Versions of documents can be created by creating "Snapshots". A snapshot is just a copy of a document at any point of time. A document can be reverted to a snapshot at any time.
As long as you provide the required snapshot resolvers, no additional server configuration is required.
To use the snapshot feature, read the client side guide on snapshots.
The rest of this guide outlines how snapshots work under the hood, as well as a couple configuration options
How snapshots work#
Creating snapshots#
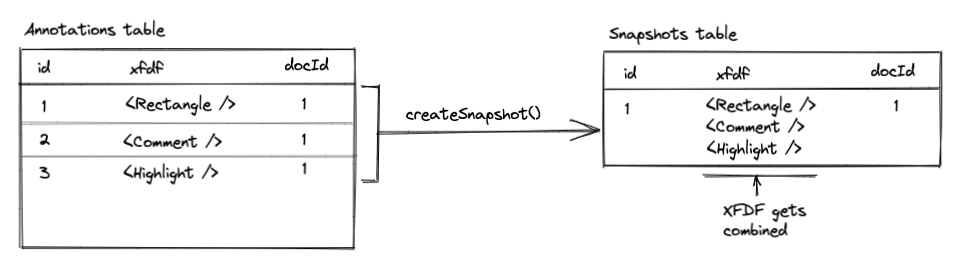
When a snapshot is created, the following operations take place:
1) The database is queried for all annotations belonging to the document
2) All the annotation's XFDF gets merged into a single XFDF string
- Note: If any of the annotations contain large base64 strings (stamps, images, signatures, etc), these assets get put into a separate snapshot assets table.
3) A new row gets added to the Snapshots table, where the XFDF content is one big XFDF string containing all the annotations at that point in time.
Previewing snapshots#
When a snapshot is previewed, we simply hide all of the current annotations on the document and render the XFDF from the chosen snapshot.
The database is not altered in any way when previewing a snapshot. The entire operation happens client side.
Restoring snapshots#
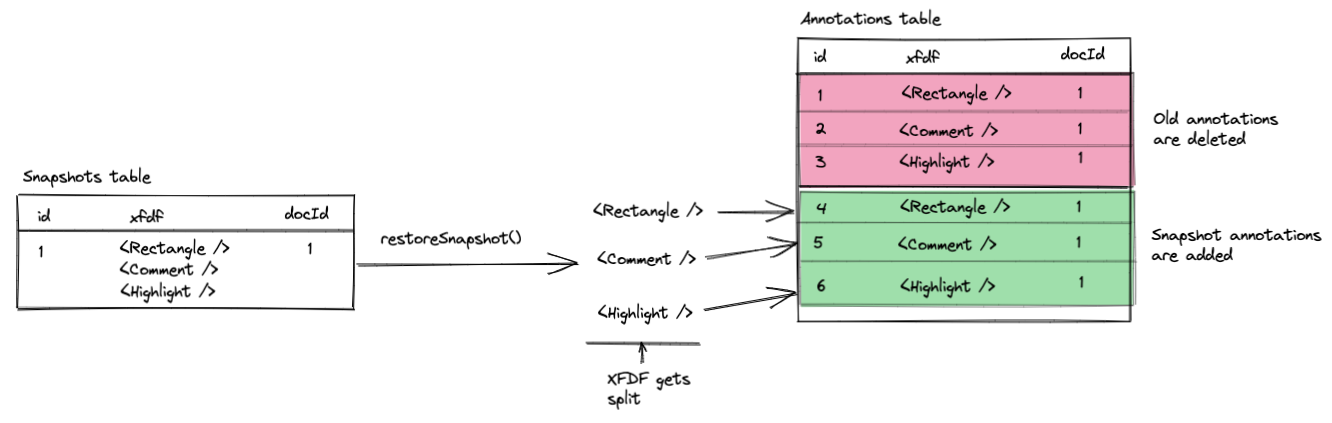
When a snapshot is restored, a few things happen:
1) A backup snapshot of the document is created using the same flow as described above.
2) The XFDF of the snapshot is split into individual XFDF strings, one per annotation
3) The split up annotations are inserted into your Annotations table
4) The old annotations are deleted
This operation is potentially destructive since it deletes all the current annotations for that document from your database.
Snapshot assets#
Some annotations can be extremely large. For example, stamp annotations typically contain a base64 encoded image which can be several MB big.
Reading large strings from a database can get very slow. Here are some results from our testing using an SQL database:
| String length (chars) | Execution time (ms) | Description |
|---|---|---|
| 10173 | 62 | 10 rectangle annotations (no base 64) |
| 1407552 | 123 | 2 stamp annots |
| 2807310 | 233 | 4 stamp annots |
| 4207068 | 394 | 6 stamp annots |
| 9106196 | 1456 | 13 stamp annots |
| 14005350 | 3216 | 20 stamp annots |
You can see that read times get exponentially longer as the size of the string increases.
This poses a problem. When creating snapshots containing many stamp annotations, we could be creating extremely large strings that can take several seconds to load from the database.
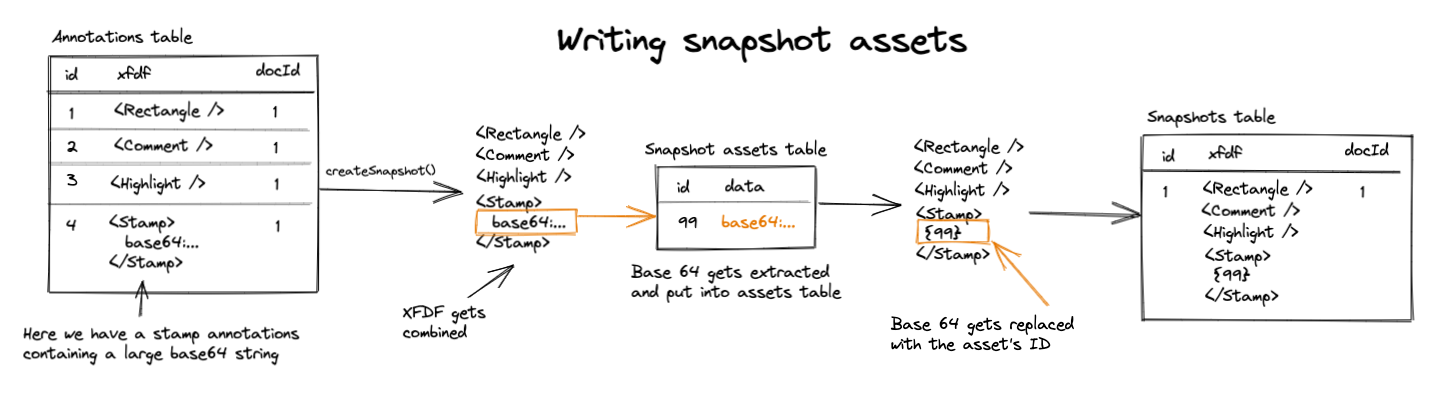
Our solution to this problem is using a snapshot assets table.
The snapshot assets table is used to store large base 64 strings, which reduces the size of our main snapshots XFDF.
When a snapshot is created, any base64 strings get pulled out and stored separately in the snapshot assets table. The original XFDF then gets a reference to that asset so it can be queried and replaced later.
Reading snapshot assets is the same process, but in reverse. We fetch the snapshots XFDF, and then replace any references to assets with the actual asset:
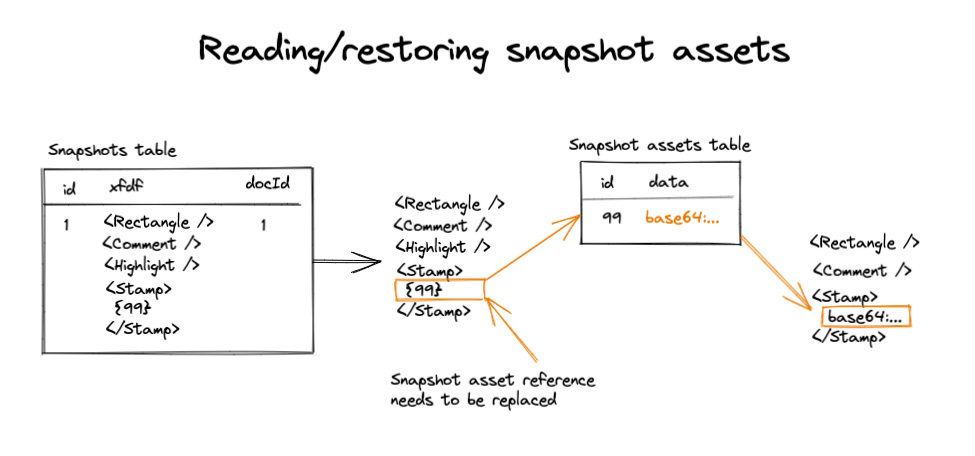
This process significantly reduces the amount of time it takes to query large XFDF strings.
Disabling snapshot assets#
If you do not want to have a separate SnapshotAssets table, this feature can be disabled by passing disableSnapshotAssets: true to the server constructor.
If snapshot assets are disabled, then the large XFDF strings will be included directly in the Snapshots table.